Hi, day12我們來講更進階的正則表達式
這次會用到以下這兩個函式
REGEXP_REPLACE(多重自訂規則取代字元)
REGEXP_EXTRACT(多重自訂規則取出字元)
話不多說, 馬上來開始今天的情境吧!
我們有代碼欄位, 欄位內容極其髒亂
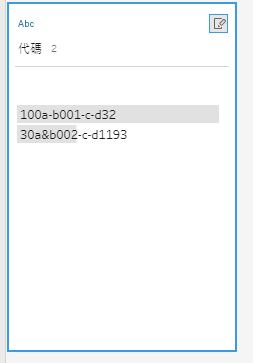
在這個情況下若我們目標是取出 b 以及 b後面的三個數字, 該怎麼做?
首先應該會有人想到用RIGHT或LEFT函式, 但並沒有符合一個特定的規則, 這樣是無法使用的
這個時候, 我們可以使用REGEXP_REPLACE函式, 先把 – 字元還有 & 字元先處理掉
函式該怎麼寫呢?
REGEXP_REPLACE([代碼], ('-|&'), '')
我們用小括號, 裡面先加上單引號表示字串, 接著輸入 | 符號表示 “或” 的意思, 那麼這段函式就可以理解成, 若代碼欄位有 ‘–‘ 或 ‘&’ 字元則取代掉, 那麼我們來看看目前的資料長相
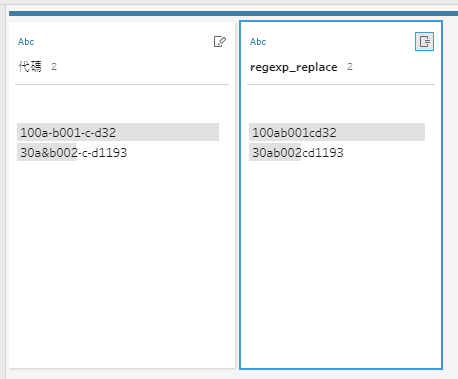
現在看起來, 若我們的目標是要取出 b 以及 b後面的三個數字, 已經有一個規則出現了
就是在b字元的前面都會有一個英文字母 a
這時候我們再使用REGEXP_EXTRACT函式取出我們要的, 該怎麼寫呢?
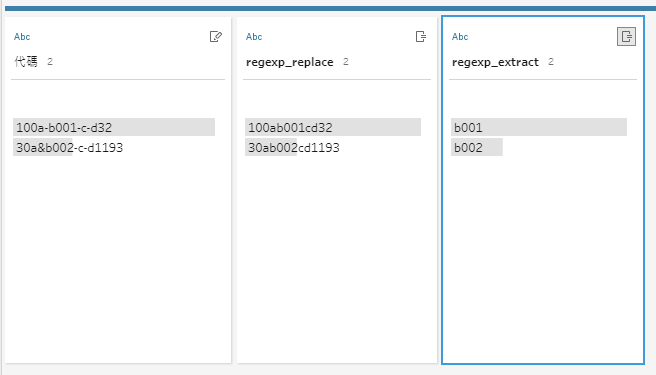
REGEXP_EXTRACT([regexp_replace], '[a]+([b]+[0-9]{3})')
解法思路&規則:
如此一來我們來看看結果就成功達到需求!
所以我們在面對髒亂無序的資料時, 要記住幾個心法
正則表達式還有許多狀況的規則寫法, 有興趣的讀者可以另行google尋找!

